Глава 16: Оптимизация с учетом ресурсов
Resource-Aware Optimization позволяет интеллектуальным агентам динамически отслеживать и управлять вычислительными, временными и финансовыми ресурсами во время работы. Это отличается от простого планирования, которое в основном фокусируется на последовательности действий. Resource-Aware Optimization требует от агентов принятия решений относительно выполнения действий для достижения целей в рамках заданных бюджетов ресурсов или для оптимизации эффективности. Это включает в себя выбор между более точными, но дорогими моделями и более быстрыми, менее затратными, или принятие решения о том, следует ли выделить дополнительные вычислительные ресурсы для более детального ответа или вернуть более быстрый, менее подробный ответ.
Например, рассмотрим агента, которому поручено проанализировать большой набор данных для финансового аналитика. Если аналитику нужен предварительный отчет немедленно, агент может использовать более быструю, доступную модель для быстрого обобщения ключевых тенденций. Однако, если аналитику требуется высокоточный прогноз для критического инвестиционного решения и у него есть больший бюджет и больше времени, агент выделит больше ресурсов для использования мощной, более медленной, но более точной прогностической модели. Ключевой стратегией в этой категории является механизм отката (fallback), который действует как защитная мера, когда предпочтительная модель недоступна из-за перегрузки или ограничений. Для обеспечения изящной деградации система автоматически переключается на резервную или более доступную модель, поддерживая непрерывность работы вместо полного отказа.
Практические применения и случаи использования
Практические случаи использования включают:
- Оптимизированное по стоимости использование LLM: Агент решает, использовать ли большую, дорогую LLM для сложных задач или меньшую, более доступную для простых запросов, основываясь на бюджетных ограничениях.
- Операции, чувствительные к задержкам: В системах реального времени агент выбирает более быстрый, но потенциально менее всеобъемлющий путь рассуждений для обеспечения своевременного ответа.
- Энергоэффективность: Для агентов, развернутых на периферийных устройствах или с ограниченным питанием, оптимизация их обработки для экономии заряда батареи.
- Резервирование для надежности сервиса: Агент автоматически переключается на резервную модель, когда основной выбор недоступен, обеспечивая непрерывность работы и изящную деградацию.
- Управление использованием данных: Агент выбирает сжатое извлечение данных вместо загрузки полного набора данных для экономии пропускной способности или хранилища.
- Адаптивное распределение задач: В многоагентных системах агенты самостоятельно назначают себе задачи на основе своей текущей вычислительной нагрузки или доступного времени.
Практический пример кода
Интеллектуальная система для ответов на вопросы пользователей может оценивать сложность каждого вопроса. Для простых запросов она использует экономичную языковую модель, такую как Gemini Flash. Для сложных запросов рассматривается более мощная, но дорогая языковая модель (например, Gemini Pro). Решение об использовании более мощной модели также зависит от доступности ресурсов, в частности, бюджета и временных ограничений. Эта система динамически выбирает подходящие модели.
Например, рассмотрим планировщик путешествий, построенный с иерархическим агентом. Высокоуровневое планирование, которое включает понимание сложного запроса пользователя, разбиение его на многоэтапный маршрут и принятие логических решений, будет управляться сложной и более мощной LLM, такой как Gemini Pro. Это "агент-планировщик", который требует глубокого понимания контекста и способности к рассуждению.
Однако, как только план установлен, отдельные задачи в рамках этого плана, такие как поиск цен на авиабилеты, проверка доступности отелей или поиск отзывов о ресторанах, по сути являются простыми, повторяющимися веб-запросами. Эти "вызовы инструментальных функций" могут выполняться более быстрой и доступной моделью, такой как Gemini Flash. Легче визуализировать, почему доступная модель может использоваться для этих простых веб-поисков, в то время как сложная фаза планирования требует большего интеллекта более продвинутой модели для обеспечения связного и логичного плана путешествия.
Google ADK поддерживает этот подход через свою многоагентную архитектуру, которая позволяет создавать модульные и масштабируемые приложения. Различные агенты могут обрабатывать специализированные задачи. Гибкость моделей позволяет прямое использование различных моделей Gemini, включая как Gemini Pro, так и Gemini Flash, или интеграцию других моделей через LiteLLM. Возможности оркестрации ADK поддерживают динамическую маршрутизацию, управляемую LLM, для адаптивного поведения. Встроенные функции оценки позволяют систематически оценивать производительность агентов, что может использоваться для совершенствования системы (см. главу об оценке и мониторинге).
Далее будут определены два агента с одинаковой настройкой, но использующие разные модели и стоимость.
# Концептуальная Python-подобная структура, не исполняемый код
from google.adk.agents import Agent
# from google.adk.models.lite_llm import LiteLlm # Если используются модели, не поддерживаемые напрямую ADK Agent по умолчанию
# Агент, использующий более дорогую Gemini Pro 2.5
gemini_pro_agent = Agent(
name="GeminiProAgent",
model="gemini-2.5-pro", # Заглушка для фактического имени модели, если отличается
description="Высокопроизводительный агент для сложных запросов.",
instruction="Вы являетесь экспертным помощником для решения сложных проблем."
)
# Агент, использующий менее дорогую Gemini Flash 2.5
gemini_flash_agent = Agent(
name="GeminiFlashAgent",
model="gemini-2.5-flash", # Заглушка для фактического имени модели, если отличается
description="Быстрый и эффективный агент для простых запросов.",
instruction="Вы являетесь быстрым помощником для простых вопросов."
)Агент-маршрутизатор может направлять запросы на основе простых метрик, таких как длина запроса, где более короткие запросы направляются к менее дорогим моделям, а более длинные запросы - к более способным моделям. Однако более сложный агент-маршрутизатор может использовать либо LLM, либо ML модели для анализа нюансов и сложности запросов. Этот LLM-маршрутизатор может определить, какая последующая языковая модель наиболее подходящая. Например, запрос, требующий фактического воспоминания, направляется к flash-модели, в то время как сложный запрос, требующий глубокого анализа, направляется к pro-модели.
Техники оптимизации могут дополнительно повысить эффективность LLM-маршрутизатора. Настройка промптов включает создание промптов для направления LLM-маршрутизатора к лучшим решениям по маршрутизации. Тонкая настройка LLM-маршрутизатора на наборе данных запросов и их оптимальных выборов моделей улучшает его точность и эффективность. Эта возможность динамической маршрутизации балансирует качество ответов с экономической эффективностью.
# Концептуальная Python-подобная структура, не исполняемый код
from google.adk.agents import Agent, BaseAgent
from google.adk.events import Event
from google.adk.agents.invocation_context import InvocationContext
import asyncio
class QueryRouterAgent(BaseAgent):
name: str = "QueryRouter"
description: str = "Направляет пользовательские запросы к соответствующему LLM агенту на основе сложности."
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
user_query = context.current_message.text # Предполагается текстовый ввод
query_length = len(user_query.split()) # Простая метрика: количество слов
if query_length < 20: # Пример порога для простоты против сложности
print(f"Направление к Gemini Flash Agent для короткого запроса (длина: {query_length})")
# В реальной настройке ADK вы бы использовали 'transfer_to_agent' или прямой вызов
# Для демонстрации мы симулируем вызов и возвращаем его ответ
response = await gemini_flash_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Flash Agent обработал: {response}")
else:
print(f"Направление к Gemini Pro Agent для длинного запроса (длина: {query_length})")
response = await gemini_pro_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Pro Agent обработал: {response}")Агент-критик оценивает ответы от языковых моделей, предоставляя обратную связь, которая выполняет несколько функций. Для самокоррекции он выявляет ошибки или несоответствия, побуждая отвечающего агента улучшить свой вывод для повышения качества. Он также систематически оценивает ответы для мониторинга производительности, отслеживая метрики, такие как точность и релевантность, которые используются для оптимизации.
Дополнительно, его обратная связь может сигнализировать об обучении с подкреплением или тонкой настройке; последовательное выявление неадекватных ответов Flash-модели, например, может улучшить логику агента-маршрутизатора. Хотя агент-критик не управляет бюджетом напрямую, он способствует косвенному управлению бюджетом, выявляя неоптимальные выборы маршрутизации, такие как направление простых запросов к Pro-модели или сложных запросов к Flash-модели, что приводит к плохим результатам. Это информирует о корректировках, которые улучшают распределение ресурсов и экономию затрат.
Агент-критик может быть настроен на рецензирование либо только сгенерированного текста от отвечающего агента, либо как исходного запроса, так и сгенерированного текста, обеспечивая всестороннюю оценку соответствия ответа исходному вопросу.
CRITIC_SYSTEM_PROMPT = """
Вы являетесь **Агентом-критиком**, выполняющим роль отдела контроля качества нашей системы совместного исследовательского помощника. Ваша основная функция - **тщательно рецензировать и подвергать сомнению** информацию от Агента-исследователя, гарантируя **точность, полноту и беспристрастную подачу**.
Ваши обязанности включают:
* **Оценку результатов исследований** на предмет фактической корректности, тщательности и потенциальных предвзятостей.
* **Выявление любых недостающих данных** или несоответствий в рассуждениях.
* **Постановку критических вопросов**, которые могли бы уточнить или расширить текущее понимание.
* **Предоставление конструктивных предложений** для улучшения или исследования различных углов зрения.
* **Проверку того, что конечный результат является всеобъемлющим** и сбалансированным.
Вся критика должна быть конструктивной. Ваша цель - укрепить исследование, а не аннулировать его. Структурируйте свою обратную связь четко, обращая внимание на конкретные моменты для пересмотра. Ваша общая цель - обеспечить соответствие конечного исследовательского продукта наивысшим возможным стандартам качества.
"""Агент-критик работает на основе предопределенного системного промпта, который описывает его роль, обязанности и подход к обратной связи. Хорошо разработанный промпт для этого агента должен четко установить его функцию как оценщика. Он должен специфицировать области для критического фокуса и подчеркивать предоставление конструктивной обратной связи, а не простого отклонения. Промпт также должен поощрять выявление как сильных, так и слабых сторон, и он должен направлять агента о том, как структурировать и представлять свою обратную связь.
Практический пример кода с OpenAI
Эта система использует стратегию оптимизации с учетом ресурсов для эффективной обработки пользовательских запросов. Она сначала классифицирует каждый запрос в одну из трех категорий, чтобы определить наиболее подходящий и экономически эффективный путь обработки. Этот подход избегает растраты вычислительных ресурсов на простые запросы, обеспечивая при этом необходимое внимание сложным запросам. Три категории:
- simple: Для простых вопросов, на которые можно ответить напрямую без сложных рассуждений или внешних данных.
- reasoning: Для запросов, требующих логического вывода или многоэтапных мыслительных процессов, которые направляются к более мощным моделям.
- internet_search: Для вопросов, требующих актуальной информации, что автоматически запускает поиск в Google для предоставления актуального ответа.
Код распространяется под лицензией MIT и доступен на Github: (https://github.com/mahtabsyed/21-Agentic-Patterns/blob/main/16_Resource_Aware_Opt_LLM_Reflection_v2.ipynb)
# MIT License
# Copyright (c) 2025 Mahtab Syed
# https://www.linkedin.com/in/mahtabsyed/
import os
import requests
import json
from dotenv import load_dotenv
from openai import OpenAI
# Загрузка переменных окружения
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GOOGLE_CUSTOM_SEARCH_API_KEY = os.getenv("GOOGLE_CUSTOM_SEARCH_API_KEY")
GOOGLE_CSE_ID = os.getenv("GOOGLE_CSE_ID")
if not OPENAI_API_KEY or not GOOGLE_CUSTOM_SEARCH_API_KEY or not GOOGLE_CSE_ID:
raise ValueError(
"Пожалуйста, установите OPENAI_API_KEY, GOOGLE_CUSTOM_SEARCH_API_KEY и GOOGLE_CSE_ID в вашем .env файле."
)
client = OpenAI(api_key=OPENAI_API_KEY)
# --- Шаг 1: Классификация промпта ---
def classify_prompt(prompt: str) -> dict:
system_message = {
"role": "system",
"content": (
"Вы классификатор, который анализирует пользовательские промпты и возвращает ТОЛЬКО одну из трех категорий:\n\n"
"- simple\n"
"- reasoning\n"
"- internet_search\n\n"
"Правила:\n"
"- Используйте 'simple' для прямых фактических вопросов, не требующих рассуждений или текущих событий.\n"
"- Используйте 'reasoning' для логических, математических вопросов или вопросов многоэтапного вывода.\n"
"- Используйте 'internet_search', если промпт ссылается на текущие события, недавние данные или вещи, отсутствующие в ваших обучающих данных.\n\n"
"Отвечайте ТОЛЬКО JSON как:\n"
'{ "classification": "simple" }'
),
}
user_message = {"role": "user", "content": prompt}
response = client.chat.completions.create(
model="gpt-4o", messages=[system_message, user_message], temperature=1
)
reply = response.choices[0].message.content
return json.loads(reply)
# --- Шаг 2: Поиск Google ---
def google_search(query: str, num_results=1) -> list:
url = "https://www.googleapis.com/customsearch/v1"
params = {
"key": GOOGLE_CUSTOM_SEARCH_API_KEY,
"cx": GOOGLE_CSE_ID,
"q": query,
"num": num_results,
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
results = response.json()
if "items" in results and results["items"]:
return [
{
"title": item.get("title"),
"snippet": item.get("snippet"),
"link": item.get("link"),
}
for item in results["items"]
]
else:
return []
except requests.exceptions.RequestException as e:
return {"error": str(e)}
# --- Шаг 3: Генерация ответа ---
def generate_response(prompt: str, classification: str, search_results=None) -> str:
if classification == "simple":
model = "gpt-4o-mini"
full_prompt = prompt
elif classification == "reasoning":
model = "o4-mini"
full_prompt = prompt
elif classification == "internet_search":
model = "gpt-4o"
# Преобразование каждого результата поиска в читаемую строку
if search_results:
search_context = "\n".join(
[
f"Заголовок: {item.get('title')}\nФрагмент: {item.get('snippet')}\nСсылка: {item.get('link')}"
for item in search_results
]
)
else:
search_context = "Результаты поиска не найдены."
full_prompt = f"""Используйте следующие веб-результаты для ответа на пользовательский запрос:
{search_context}
Запрос: {prompt}"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": full_prompt}],
temperature=1,
)
return response.choices[0].message.content, model
# --- Шаг 4: Объединенный маршрутизатор ---
def handle_prompt(prompt: str) -> dict:
classification_result = classify_prompt(prompt)
# Удалите или закомментируйте следующую строку, чтобы избежать дублирования вывода
# print("\n🔍 Результат классификации:", classification_result)
classification = classification_result["classification"]
search_results = None
if classification == "internet_search":
search_results = google_search(prompt)
# print("\n🔍 Результаты поиска:", search_results)
answer, model = generate_response(prompt, classification, search_results)
return {"classification": classification, "response": answer, "model": model}
test_prompt = "Какая столица Австралии?"
# test_prompt = "Объясните влияние квантовых вычислений на криптографию."
# test_prompt = "Когда начинается Australian Open 2026, дайте мне полную дату?"
result = handle_prompt(test_prompt)
print("🔍 Классификация:", result["classification"])
print("🤖 Используемая модель:", result["model"])
print("🤖 Ответ:\n", result["response"])Этот код Python реализует систему маршрутизации промптов для ответов на вопросы пользователей. Он начинает с загрузки необходимых API ключей из .env файла для OpenAI и Google Custom Search. Основная функциональность заключается в классификации промпта пользователя в одну из трех категорий: simple, reasoning или internet search. Специальная функция использует модель OpenAI для этого шага классификации. Если промпт требует актуальной информации, выполняется поиск Google с использованием Google Custom Search API. Другая функция затем генерирует финальный ответ, выбирая подходящую модель OpenAI на основе классификации. Для запросов интернет-поиска результаты поиска предоставляются как контекст модели. Основная функция handle_prompt координирует этот рабочий процесс, вызывая функции классификации и поиска (при необходимости) перед генерацией ответа. Она возвращает классификацию, используемую модель и сгенерированный ответ. Эта система эффективно направляет различные типы запросов к оптимизированным методам для лучшего ответа.
Практический пример кода (OpenRouter)
OpenRouter предлагает унифицированный интерфейс к сотням AI-моделей через единую конечную точку API. Он обеспечивает автоматический отказоустойчивость и оптимизацию затрат с легкой интеграцией через предпочитаемый SDK или framework.
import requests
import json
response = requests.post(
url="https://openrouter.ai/api/v1/chat/completions",
headers={
"Authorization": "Bearer <OPENROUTER_API_KEY>",
"HTTP-Referer": "<YOUR_SITE_URL>", # Опционально. URL сайта для рейтингов на openrouter.ai.
"X-Title": "<YOUR_SITE_NAME>", # Опционально. Название сайта для рейтингов на openrouter.ai.
},
data=json.dumps({
"model": "openai/gpt-4o", # Опционально
"messages": [
{
"role": "user",
"content": "В чем смысл жизни?"
}
]
})
)Этот фрагмент кода использует библиотеку requests для взаимодействия с OpenRouter API. Он отправляет POST-запрос к конечной точке завершения чата с пользовательским сообщением. Запрос включает заголовки авторизации с API ключом и опциональную информацию о сайте. Цель - получить ответ от указанной языковой модели, в данном случае "openai/gpt-4o".
Openrouter предлагает две различные методологии для маршрутизации и определения вычислительной модели, используемой для обработки данного запроса.
- Автоматический выбор модели: Эта функция направляет запрос к оптимизированной модели, выбранной из кураторского набора доступных моделей. Выбор основывается на конкретном содержании промпта пользователя. Идентификатор модели, которая в конечном итоге обрабатывает запрос, возвращается в метаданных ответа.
{
"model": "openrouter/auto",
... // Другие параметры
}- Последовательный отказ модели: Этот механизм обеспечивает операционную избыточность, позволяя пользователям указывать иерархический список моделей. Система сначала попытается обработать запрос с основной моделью, указанной в последовательности. Если эта основная модель не сможет ответить из-за любого количества условий ошибки — таких как недоступность сервиса, ограничение скорости или фильтрация контента — система автоматически перенаправит запрос к следующей указанной модели в последовательности. Этот процесс продолжается до тех пор, пока модель в списке успешно не выполнит запрос или список не будет исчерпан. Финальная стоимость операции и идентификатор модели, возвращаемые в ответе, будут соответствовать модели, которая успешно завершила вычисление.
{
"models": ["anthropic/claude-3.5-sonnet", "gryphe/mythomax-l2-13b"],
... // Другие параметры
}OpenRouter предлагает подробную таблицу лидеров (https://openrouter.ai/rankings), которая ранжирует доступные AI-модели на основе их совокупного производства токенов. Он также предлагает последние модели от различных провайдеров (ChatGPT, Gemini, Claude) (см. Рис. 1)
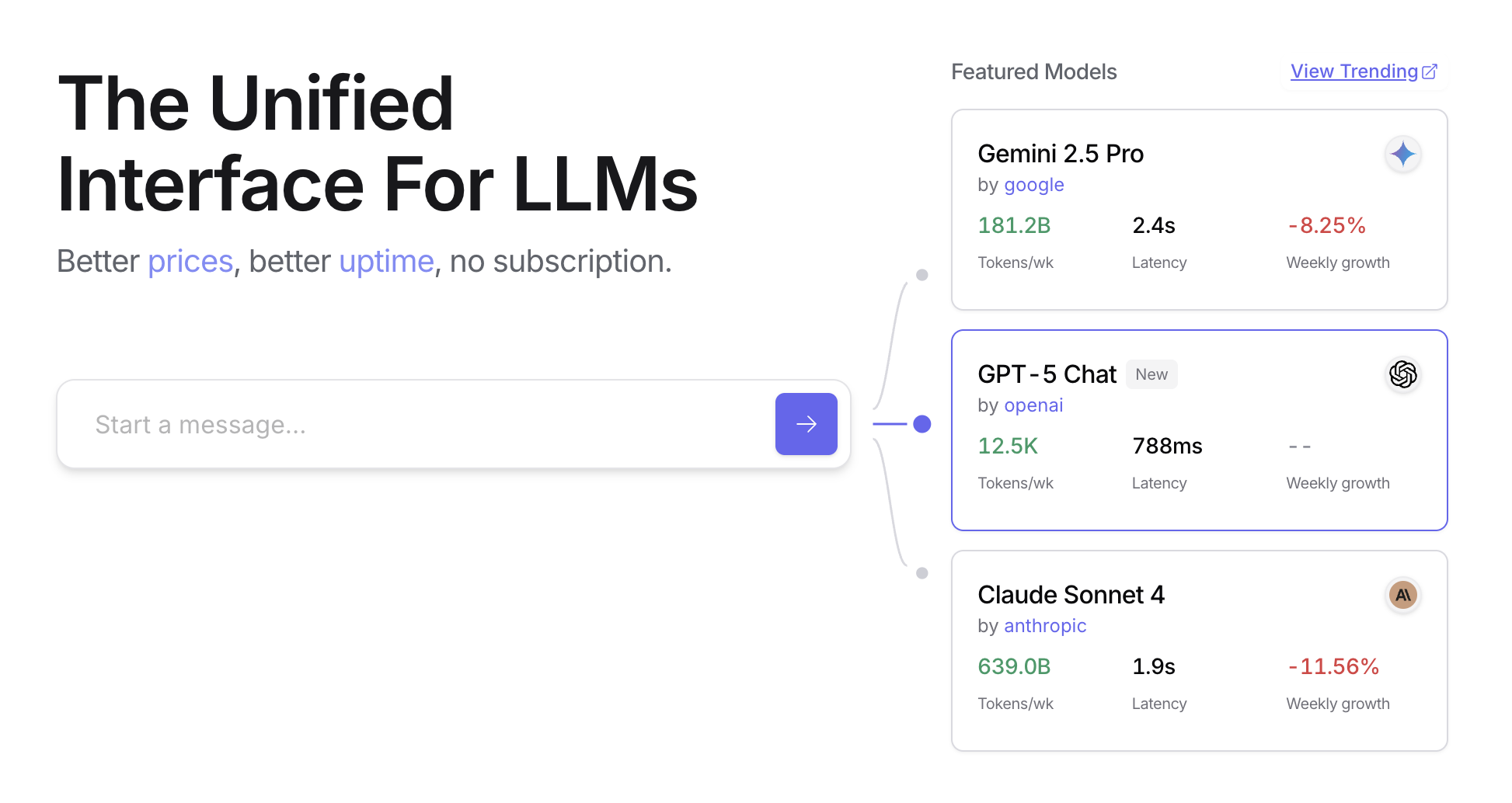
Рис. 1: Веб-сайт OpenRouter (https://openrouter.ai/)
За пределами динамического переключения моделей: Спектр оптимизаций ресурсов агентов
Оптимизация с учетом ресурсов имеет первостепенное значение при разработке систем интеллектуальных агентов, которые работают эффективно и результативно в условиях реальных ограничений. Рассмотрим ряд дополнительных техник:
Динамическое переключение моделей является критически важной техникой, включающей стратегический выбор больших языковых моделей на основе сложности поставленной задачи и доступных вычислительных ресурсов. При работе с простыми запросами может быть развернута легковесная, экономически эффективная LLM, в то время как сложные, многогранные проблемы требуют использования более сложных и ресурсоемких моделей.
Адаптивное использование и выбор инструментов обеспечивает интеллектуальный выбор агентами из набора инструментов, выбирая наиболее подходящий и эффективный для каждой конкретной подзадачи, с тщательным учетом таких факторов, как стоимость использования API, задержка и время выполнения. Этот динамический выбор инструментов повышает общую эффективность системы за счет оптимизации использования внешних API и сервисов.
Контекстное сокращение и суммаризация играет жизненно важную роль в управлении объемом информации, обрабатываемой агентами, стратегически минимизируя количество токенов промпта и снижая затраты на вывод путем интеллектуального суммирования и селективного сохранения только наиболее релевантной информации из истории взаимодействий, предотвращая ненужные вычислительные накладные расходы.
Проактивное предсказание ресурсов включает предвидение потребностей в ресурсах путем прогнозирования будущих рабочих нагрузок и системных требований, что позволяет проактивно распределять и управлять ресурсами, обеспечивая отзывчивость системы и предотвращая узкие места.
Исследование с учетом стоимости в многоагентных системах расширяет соображения оптимизации, охватывая стоимость коммуникации наряду с традиционными вычислительными затратами, влияя на стратегии, используемые агентами для сотрудничества и обмена информацией, стремясь минимизировать общие расходы на ресурсы.
Энергоэффективное развертывание специально адаптировано для сред со строгими ресурсными ограничениями, направлено на минимизацию энергетического следа систем интеллектуальных агентов, продление времени работы и снижение общих эксплуатационных затрат.
Осведомленность о параллелизации и распределенных вычислениях использует распределенные ресурсы для повышения вычислительной мощности и пропускной способности агентов, распределяя вычислительные рабочие нагрузки по нескольким машинам или процессорам для достижения большей эффективности и более быстрого завершения задач.
Изученные политики распределения ресурсов вводят механизм обучения, позволяя агентам адаптироваться и оптимизировать свои стратегии распределения ресурсов со временем на основе обратной связи и метрик производительности, улучшая эффективность через непрерывное совершенствование.
Изящная деградация и механизмы отката гарантируют, что системы интеллектуальных агентов могут продолжать функционировать, хотя и возможно с пониженной производительностью, даже когда ресурсные ограничения серьезны, изящно снижая производительность и переходя к альтернативным стратегиям для поддержания работы и обеспечения основной функциональности.
Краткий обзор
Что: Resource-Aware Optimization решает задачу управления потреблением вычислительных, временных и финансовых ресурсов в интеллектуальных системах. Приложения на основе LLM могут быть дорогими и медленными, и выбор лучшей модели или инструмента для каждой задачи часто неэффективен. Это создает фундаментальный компромисс между качеством вывода системы и ресурсами, необходимыми для его производства. Без стратегии динамического управления системы не могут адаптироваться к изменяющейся сложности задач или работать в рамках бюджетных и производительных ограничений.
Почему: Стандартизированное решение заключается в построении агентной системы, которая интеллектуально отслеживает и распределяет ресурсы на основе поставленной задачи. Этот шаблон обычно использует "Агента-маршрутизатора" для первоначальной классификации сложности входящего запроса. Затем запрос направляется к наиболее подходящей LLM или инструменту — быстрой, недорогой модели для простых запросов и более мощной для сложных рассуждений. "Агент-критик" может дополнительно улучшить процесс, оценивая качество ответа, предоставляя обратную связь для улучшения логики маршрутизации со временем. Этот динамический, многоагентный подход обеспечивает эффективную работу системы, балансируя качество ответов с экономической эффективностью.
Практическое правило: Используйте этот шаблон при работе в условиях строгих финансовых бюджетов для API-вызовов или вычислительной мощности, создании приложений, чувствительных к задержкам, где критически важно быстрое время ответа, развертывании агентов на ресурсно-ограниченном оборудовании, таком как периферийные устройства с ограниченным временем работы батареи, программном балансировании компромисса между качеством ответа и операционными затратами, а также управлении сложными, многоэтапными рабочими процессами, где различные задачи имеют различные требования к ресурсам.
Визуальное резюме

Рис. 2: Шаблон проектирования Resource-Aware Optimization
Ключевые выводы
- Resource-Aware Optimization является необходимой: Интеллектуальные агенты могут динамически управлять вычислительными, временными и финансовыми ресурсами. Решения относительно использования моделей и путей выполнения принимаются на основе ограничений и целей в реальном времени.
- Многоагентная архитектура для масштабируемости: Google ADK предоставляет многоагентный framework, обеспечивающий модульный дизайн. Различные агенты (отвечающие, маршрутизирующие, критикующие) обрабатывают конкретные задачи.
- Динамическая маршрутизация, управляемая LLM: Агент-маршрутизатор направляет запросы к языковым моделям (Gemini Flash для простых, Gemini Pro для сложных) на основе сложности запроса и бюджета. Это оптимизирует стоимость и производительность.
- Функциональность агента-критика: Специализированный агент-критик предоставляет обратную связь для самокоррекции, мониторинга производительности и совершенствования логики маршрутизации, повышая эффективность системы.
- Оптимизация через обратную связь и гибкость: Возможности оценки для критики и гибкость интеграции моделей способствуют адаптивному и самосовершенствующемуся поведению системы.
- Дополнительные оптимизации с учетом ресурсов: Другие методы включают адаптивное использование и выбор инструментов, контекстное сокращение и суммаризацию, проактивное предсказание ресурсов, исследование с учетом стоимости в многоагентных системах, энергоэффективное развертывание, осведомленность о параллелизации и распределенных вычислениях, изученные политики распределения ресурсов, изящную деградацию и механизмы отката, а также приоритизацию критических задач.
Заключения
Оптимизация с учетом ресурсов является необходимой для разработки интеллектуальных агентов, обеспечивая эффективную работу в условиях реальных ограничений. Управляя вычислительными, временными и финансовыми ресурсами, агенты могут достичь оптимальной производительности и экономической эффективности. Техники, такие как динамическое переключение моделей, адаптивное использование инструментов и контекстное сокращение, имеют решающее значение для достижения этих эффективностей. Продвинутые стратегии, включая изученные политики распределения ресурсов и изящную деградацию, повышают адаптивность и устойчивость агента в различных условиях. Интеграция этих принципов оптимизации в дизайн агентов является фундаментальной для построения масштабируемых, надежных и устойчивых AI-систем.
Литература
- Google Agent Development Kit (ADK): https://google.github.io/adk-docs/
- Gemini Flash 2.5 & Gemini 2.5 Pro: https://aistudio.google.com/
- OpenRouter: https://openrouter.ai/docs/quickstart
Навигация
Назад: Глава 15. Межагентная коммуникация
Вперед: Глава 17. Техники рассуждения